
Human societies have always relied on social connection. Today, with the web this is even more true, isn't the internet a huge nebuleous of data ? Networks are also present in our brain, or used to model energy transit.
The goal of this post is to explain how we can interact with graphs supporting one-dimensionnal signals: from data to processing.
tl;dr¶
- Create the adjacency matrix with the appropriate similarity metric.
- Compute the graph laplacian (from the adjacency matrix) and solve its eigen vectors.
- Transform the input graph signal into the spectral domain using the laplacian eigen vectors.
- Enjoy applying any graph convolution on your data!
1. Mathematical background¶
1.1 Graph definition¶
Mathematically, a graph is a pair $G = (V , E)$ where $V$ is the set of vertices, and $E$ are the edges. The vertice or node represent the actual data that is broadcasted through the graph. Each node sends its own signal that propagates through the network. The edges define the relation between these nodes with the weight $w$, the more weighted is the edge, the stronger the relation between two nodes. Some examples of weights can be the vertices distance, signal correlation or even mutual information...
There are many properties for a graph, but the most important one is the directions of the edges. We say that a graph is undirected if for two nodes $a$ and $b$, $w_{ab} = w_{ba}$.
Let's look at the following example which is an unweighted undirected graph (if it was directed we would add arrows instead of lines).
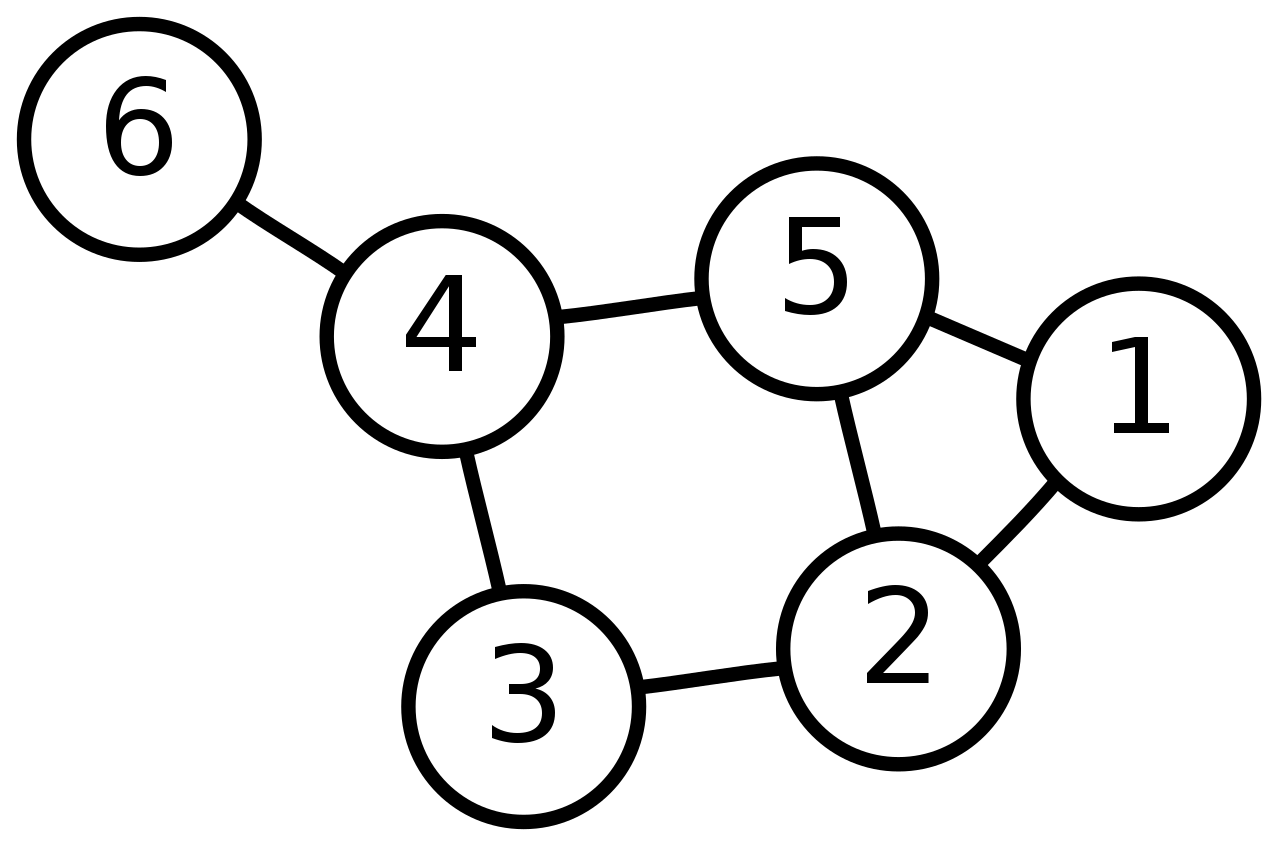
We can use this adjacency matrix $A$ to represent it numerically: \begin{equation} A = \begin{pmatrix} 0 & 1 & 0 & 0 & 1 & 0\\ 1 & 0 & 1 & 0 & 1 & 0\\ 0 & 1 & 0 & 1 & 0 & 0\\ 0 & 0 & 1 & 0 & 1 & 1\\ 1 & 1 & 0 & 1 & 0 & 0\\ 0 & 0 & 0 & 1 & 0 & 0\\ \end{pmatrix} \end{equation}
Each row correspond to the starting node, each column is the ending node. Because it is unweighted, all weights are fixed to $1$, and because it is undirected, the adjecency matrix is symmetric.
In graph signal processing (GSP), the object of study is not the network itself but a signal supported on the vertices of the graph. The graph provides a structure that can be exploited in the data processing. The signal can be any dimension like a single pixel value in an image, images captured by different people or traffic data from radars as we will see after!
If we would assign a random gaussian number for each node of the previous example, the input graph signal $X$ would look like this:
\begin{equation} X = \begin{pmatrix} -1.1875 \\ -0.1841 \\ -1.1499 \\ -1.8298 \\ 1.9561 \\ 0.6322 \end{pmatrix} \end{equation}For multi-dimensionnal signals (images, volumes), it is common to embed those into a one-dimensionnal latent space to simplify the graph processing. For example if you are working with text features (this could be a tweet from one user, or e-mails), one may use word2vec [1].
1.2 Processing graph signals¶
What we want is to be able to perform operations on those node signals, taking into account the structure of the graph. The most common operation is to filter the signal, or in mathematical term a convolution between a filter $h$ and a function $y$. For example in the temporal domain $t$: \begin{equation} y(t) \circledast h(t) = \int_{-\infty}^{+\infty}{y(t-\tau) h(\tau) d\tau} \end{equation}
Sadly, this is not directly possible in the graph (vertex) domain because the signal translation with $\tau$ is not defined in the context of graphs [2]. How do you perform the convolution then ?
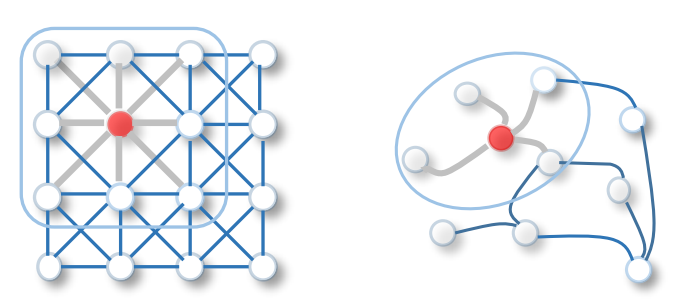
Hopefully, it is much more simple to convolve in the frequency (spectral) domain because we don't need the shift operator. This is also usefull in general in signal processing because it is less intensive computationnally: \begin{equation} \label{fourierconvolution} y(t) \circledast h(t) = Y(\omega) \cdot H(\omega) \end{equation}
To transform the input data (function) into the frequency domain, we use the widely known fourier transform.
It is a reversible, linear transformation that is just the decomposition of a signal into a new basis formed by complex exponentials. The set of complex exponentials are obviously orthogonal (independent) which is a fundamental property to form a basis.
\begin{equation} y(t) \xrightarrow{\mathscr{F}} Y(\omega) = \int_{-\infty}^{\infty} \! y(t) \mathrm{e}^{-i\omega t}\, dt \end{equation}Note:
In practice, it is not purely reversible because we lose information when applying a fourier transform. Indeed we cannot affoard computationnally to integrate the function over the infinity! We usually use the DFT (Discrete Fourier Transform), which make sense numerically with digital data.
However this formula works in the temporal domain and cannot be applied as is for signal in the graph domain $G$, so how do you define a graph fourier transform ? For that we first need to understand eigen decomposition of the laplacian and its connection to the fourier transform...
1.3 Relation between fourier transform and eigen decomposition¶
The eigen decomposition is a process that is heavily used in data dimension algorithms. For any linear transformation $T$, it exists a non-zero vector (function) $\textbf{v}$ called eigen vector (function) such as:
\begin{equation} \label{eq:eigenfunction} T(\textbf{v}) = \lambda \textbf{v} \end{equation}Where $\lambda$ is a scalar corresponding to the eigen values, i.e. the importance of each eigen vector. This formula basically means that when we apply the matrix $T$ on $\mathbf{v}$, the resulting vector is co-linear to $\mathbf{v}$. And so $\mathbf{v}$ can be used to define a new orthonormal basis for $T$!
What is of interest for us is that the complex exponential $\mathrm{e}^{i\omega t}$ is also an eigen function for the laplacian operator $\Delta$. Following eq \ref{eq:eigenfunction}, we can derive: \begin{equation} \Delta(e^{i \omega t}) = \frac{\partial^2}{\partial{t^2}} e^{i \omega t} = -\omega^2 e^{i\omega t} \end{equation}
With $\mathbf{v}=e^{i \omega t}$ and eigen values $\lambda = -\omega^2$, which makes sense since we are decomposing the temporal signal into the frequency domain!
We can rewrite the fourier transform $Y(\omega)$ using the conjugate of the eigen function of the laplacian $\mathbf{v}^*$:
\begin{equation} \label{eq:fouriereigen} Y(\omega) = \int_{-\infty}^{\infty} \! y(t) \mathbf{v}^*\,dt \end{equation}In other word, the expansion of $y$ in term of complex exponential (fourier tranform) is analogeous to the expansion of $y$ in terms of the eigenvectors of the laplacian. Still that does not help on how to apply that to graphs!
1.4 Graph fourier transform¶
There is one specific operation that is well defined for a graph, yes it is the laplacian operator. This is the connection we were looking for and we have now a way to define the graph fourier transform $\mathscr{G}_\mathscr{F}$ !
The graph lalacian $L$ is the second order derivative for a graph, and is simply defined as:
\begin{equation} L = D-A \end{equation}Where $D$ is the degree matrix that represent the number of nodes connected (including itself).
Intuitively, the graph Laplacian shows in what directions and how smoothly the “energy” will diffuse over a graph if we put some “potential” in node $i$. With the previous example it would be:
\begin{equation} L = \begin{pmatrix} 3 & 0 & 0 & 0 & 0 & 0\\ 0 & 4 & 0 & 0 & 0 & 0\\ 0 & 0 & 3 & 0 & 0 & 0\\ 0 & 0 & 0 & 4 & 0 & 0\\ 0 & 0 & 0 & 0 & 4 & 0\\ 0 & 0 & 0 & 0 & 0 & 2\\ \end{pmatrix} - \begin{pmatrix} 0 & 1 & 0 & 0 & 1 & 0\\ 1 & 0 & 1 & 0 & 1 & 0\\ 0 & 1 & 0 & 1 & 0 & 0\\ 0 & 0 & 1 & 0 & 1 & 1\\ 1 & 1 & 0 & 1 & 0 & 0\\ 0 & 0 & 0 & 1 & 0 & 0\\ \end{pmatrix} \end{equation}A node that is connected to many other nodes will have a much bigger influence than its neighbours. To mitigate this, it is common to normalize the laplacian matrix using the following formula:
\begin{equation}\label{eq:normlaplacian} L = I - D^{-1/2}AD^{-1/2} \end{equation}Whith the identity matrix $I$.
After computing the eigen vectors $\mathbf{v}$ for the graph laplacian $L$, we can derive the numeric version of the graph fourier transform $\mathcal{G}$ for $N$ vertices from eq \ref{eq:fouriereigen}:
\begin{equation} \label{eq:graphfouriernumeric} x(i) \xrightarrow{\mathscr{G}_\mathscr{F}} X(\lambda_l) =\sum_{i=0}^{N-1} x(i)\mathbf{v}_l^T(i) \end{equation}With $x(i)$ being the signal for node $i$ in the graph/vertex domain, which was a single value in our first example.
The matrix form is:
\begin{equation} \label{eq:matrixgraphfouriernumeric} \hat{X} = V^TX \end{equation}1.5 Global graph convolution¶
Now that we can transform the input data from graph/vertex domain (node $i$) to the spectral domain (frequency $\lambda_l$), we can apply the previous eq \ref{fourierconvolution} to perform graph convolution. We perform the convolution of the data $x$ with filter $h$ into the spectral domain $\lambda_l$, but we want our outputs to be in the graph domain $i$:
\begin{align} x(i) \circledast h(i) & = \mathcal{G}^{-1}(\mathcal{G}(x(i) \circledast h(i))) & \\ & = \sum_{l=0}^{N-1} \hat{x}(\lambda_l) \cdot \hat{g}(\lambda_l) \cdot \mathbf{v}_l^T(i) & \\ \end{align}and its matrix form [3]:
\begin{align}\label{eq:graphconv} X \circledast H & = V \hat{H} * (V^T X) \end{align}Warning:
Be carefull of the element wise multiplication in the spectral domain between the filter $\hat{H}$ and transformed data $V^TX$!
One drawback with this method is that is does not work well for dynamic graphs (structure that changes in time) because the eigen vector needs to be recomputed each time! You can also see that this operation is quite complex, hopefully it can be simplified using for example Chebyshev polynomials [4]. The Chebyshev approximation allows to perform local convolution (taking into acount just adjacent nodes) instead of global convolution, which reduces consequently the compute time.
2. Hands on¶
Enough theory, now let's get our hands dirty. We will look into traffic data from the Bay Area and try to analyze it using graph processing.
2.1 Input Data¶
The data that we will be using was originally studied for trafic forecasting in [5]. It consist of a structure with several sensors in the bay area (California) that acquired the speed of cars (in miles/hour) during 6 months of year 2017. It is available publically and was collected by California Transportation Agencies Performance Measurement System (PeMS).
There are two files, sensor_locations_bay_area.csv consists of the locations of each sensor (that can be used to define the structure of the graph), the other file traffic_bay_area.csv includes the drivers speed gathered by each sensor (the node feature).
### imports
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import plotly.express as px
import numpy as np
import IPython.display
import scipy
import scipy.stats
import networkx as nx
# reading data
df = pd.read_csv("data/gsp/traffic_bay_area.csv")
df.set_index("Date")
IPython.display.display(df)
data = df.to_numpy()[:, 1:].astype(np.float32).T
# select a specific date for further analysis
start = np.where(df["Date"] == "2017-04-03 00:00:00")[0][0]
end = np.where(df["Date"] == "2017-04-03 23:30:00")[0][0]
end_3 = np.where(df["Date"] == "2017-04-06 23:30:00")[0][0]
#other variables
sensor_ids = df.columns[1:].astype(np.str)
num_nodes = len(sensor_ids)
All the sensors are located in the Bay Area of San francisco, as you can see with the following map.
# get sensor locations
locs_df = pd.read_csv("data/gsp/sensor_locations_bay_area.csv")
locs = locs_df.to_numpy()[:, 1:]
### Plot sensor locations on a map
# /!\ This is specific for liquid to escape the braces
fig = px.scatter_mapbox(locs_df, lat="lattitude", lon="longitude", hover_name="sensor_id",
color_discrete_sequence=["red"], zoom=9.5)
fig.update_layout(mapbox_style="stamen-terrain", margin={"r": 0,"t": 0,"l": 0,"b": 0}, height=400)
fig.show(renderer="iframe_connected", config={'showLink': False})
# {% end raw %}
2.2 Graph construction¶
The most important step when constructing a graph is how to define the relationships between nodes. Mathematically, we craft a positive metric bounded between $[0, 1]$ that should be high when the relation between those two nodes is strong, and as much linear as possible. Then we can model the graph using the adjacency matrix, where each line/column index being one node ID.
Here we use the euclidean distance between nodes as a metric (the distance matrix $D$). To simplify this post, we will suppose a weighted undirected graph (which in practice is maybe not ideal since cars go in one direction).
2.2.1 Adjacency matrix¶
Let's first try to build the adjacency matrix using the sensor locations. We will compute the euclidean distance between each sensor to define the realtionship between nodes.
We are working with geodesic position which lives on a sphere, hence it is not advised to directly use those positions to compute the euclidean distances. First, we need to project those into a plane, following the assumption that the measurements are close to each other, one can use the equirectangular projection.
# equirectangular projection from geodesic positions
locs_radian = np.radians(locs)
phi0 = min(locs_radian[:, 0]) + (max(locs_radian[:, 0]) - min(locs_radian[:, 0]))/2
r = 6371 #earth radius 6371 km
locs_xy = np.array([r*locs_radian[:, 1]*np.cos(phi0), r*locs_radian[:, 0]]).T
Now we can compute the distances.
# euclidean distance matrix
Xi, Xj = np.meshgrid(locs_xy[:, 0], locs_xy[:, 0])
Yi, Yj = np.meshgrid(locs_xy[:, 1], locs_xy[:, 1])
D = (Xi - Xj)**2 + (Yi - Yj)**2
max_distance = np.max(D)
print(f"Maximum squared distance is: {max_distance:.3f}km2")
We craft the adjacency matrix $A$ by inverting and normalizing the current distance matrix $D$, so the edge weights are high when the relation is high (nodes are spatially closed). The resulting distance matrix is symmetric, with the number of rows/columns equal to the number of sensors.
# create adjencency matrix
A = np.copy(D)
#inverting
A = np.max(A) - A
#normalizing
A = A / np.max(A)
### plotting original adjacency
def plot_adjacency(A, title="", xlabel="", vmin=0, vmax=1):
'''Plot the adjacency matrix with histogram'''
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 5))
img = ax[0].imshow(A, cmap="hot", vmin=vmin, vmax=vmax)
plt.colorbar(img, ax=ax[0])
ax[0].set_xlabel("Node $i$")
ax[0].set_title(title)
ax[1].hist(A[A>0].flatten())
ax[1].set_xlabel(xlabel)
plot_adjacency(A, title="Adjacency matrix", xlabel="Squared distance (km2)")

2.2.2 Pre-processing the graph¶
Because we have lot of nodes (325 sensors), the resulting graph is huge with more than $325\times325>1e^7$ edges! Using a graph that has lot of edges is not practical in our case, as this would require more CPU power with high RAM usage, hence we need to downsample the graph.
The topic of downsampling or pre-processing spatiotemporal graph is itself really active [6], here we use a simple thresholded approach called nearest neighbor graph (k-nn): keep the $k$ most important neighbor (for each node). This prevents orphan nodes compare to a basic thresholding approach.
Another additionnal process is removing the so-called "self-loops" (i.e. make the diagonal zero), so nodes does not have a relation with themself.
# thresholded adjacency matrix
k = 20
#removing self loops
np.fill_diagonal(A, 0)
#get nn thresholds from quantile
quantile_h = np.quantile(A, (num_nodes - k)/num_nodes, axis=0)
mask_not_neighbours = (A < quantile_h[:, np.newaxis])
A[mask_not_neighbours] = 0
A = (A + A.transpose())/2
A = A / np.max(A)
Looking at the adjacency matrix itself, it is now much cleaner. We see that the adjacency matrix is really sparse, this is because sensors indexes does not have spatial meaning (sensor $i=0$ and $i=1$ can be far away).
###plotting
plot_adjacency(A, title="Pre-processed adjacency matrix")

But is it logical to just use the distance matrix as a metric? What happens if there are sensors that are spatially really close, but not on the same lane?
Take for example two sensors #400296 and #401014 (near the highway interchange California 237/Zanker road on the map) and let's look at their traffic measurements on Monday 3 Apr 2017.
### plot 2 uncorrelated sensors, but spatially close (#400296 and #401014)
def get_data_sensor(sensor_name, sensor_ids, start=0, end=None):
'''Get the measurement from a sensor name'''
idx = np.where(sensor_ids == sensor_name)[0][0]
sensor_data = data[idx, start:end]
return sensor_data, idx
def plot_sensor_data_comparison(sensor1_name, sensor2_name):
'''Plot a a view of two sensors, for comparison.'''
#get sensor data
sensor1_data, sensor1_idx = get_data_sensor(sensor_name=sensor1_name, sensor_ids=sensor_ids, start=start, end=end)
sensor2_data, sensor2_idx = get_data_sensor(sensor_name=sensor2_name, sensor_ids=sensor_ids, start=start, end=end)
#plot
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10,4))
ax[0].plot(sensor1_data)
ax[0].set_title("Data for sensor {}".format(sensor1_name))
ax[1].plot(sensor2_data)
_ = ax[1].set_title("Data for sensor {}".format(sensor2_name))
#correlation
corr = np.corrcoef(sensor1_data, sensor2_data)[0, 1]
print("Distance of {:.3f}km with correlation of {:.3f}".format(np.sqrt(D[sensor1_idx, sensor2_idx]), corr))
sensor1_name = "400296"
sensor2_name = "401014"
plot_sensor_data_comparison(sensor1_name, sensor2_name)

Those are really uncorrelated, whereas the more distant sensors #400296 and #400873 are much more correlated (because they are on the same direction lane).
### plot 2 correlated sensors (#400296 and #400873)
sensor1_name = "400296"
sensor2_name = "400873"
plot_sensor_data_comparison(sensor1_name, sensor2_name)

To take into account this, we use the correlation matrix to filter out "bad" edges. We compute the correlation just for a single day (to mitigate seasonal effects), and every edges that have a correlation less than $0.6$ will be disgarded.
# correlation matrix and filtering
C = np.cov(data[:, start:end])
Cj, Ci = np.meshgrid(np.diag(C), np.diag(C))
C = np.abs(C/(np.sqrt(Ci*Cj)))
# correlation matrix and filtering
A = A * (C > 0.7)
2.2.3 Analyzis and visualization¶
### plot graph
#nx variables
pos = {i : (locs_xy[i, 0], locs_xy[i, 1]) for i in range(num_nodes)}
nx_graph = nx.from_numpy_matrix(A)
#rendering
fig, ax = plt.subplots(figsize=(8, 8))
nx.draw(nx_graph, pos, node_size=100, node_color='b', ax=ax)
_ = ax.set_title("Graph of traffic data from bay area")

This graph mainly follows the structure of the main roads in the bay area, because this is where the sensors are. Still, it also features some interconnections mostly due to the inner road connexions of the city.
2.3 Spectral decomposition¶
Now that we defined the graph structure, we can start the spectral decomposition. We will need that to perform the graph convolution, and there are also interresting visualization to better understand the graph structure.
2.3.1 Normalized laplacian matrix¶
As a reminder, we apply the eq \ref{eq:normlaplacian} using the degree matrix and the adjacency matrix.
# Degree and laplacian matrix for distance and correlation graph
degree_matrix = np.diag(np.sum(A > 0, axis=0))
np.seterr(divide='ignore')
degree_matrix_normed = np.power(degree_matrix, -0.5)
degree_matrix_normed[np.isinf(degree_matrix_normed)] = 0
L = np.identity(num_nodes) - (degree_matrix_normed @ A @ degree_matrix_normed)
### plot
plot_adjacency(-L, title="Laplacian matrix", vmin=0, vmax=0.2)

2.3.2 Eigen decomposition¶
After the laplacian is defined, we can now eigen decompose the matrix. Because our matrix is real and symmetric, we can use np.linalg.eigh which is faster than the original np.linalg.eig.
# Eigen decomposition
l, v = np.linalg.eigh(L) #lambda:l eigen values; v: eigenvectors
An important thing to check is if the eigen vectors carries a notion of frequency, for a graph that is simply the number of time each eigen vector change sign, or number of zero-crossings [8].
# zero-crossing
derivative = np.diff(np.sign(v), axis=0)
zero_crossings = np.sum(np.abs(derivative > 0), axis=0)
Minus the noise, the tendency is that the larger the eigen values $\lambda_l$, the higher the frequency (more zero-crossings between nodes). Also all the eigen values are positive, that would not be the case if the laplacian matrix was not symmetric.
### plot zero crossings
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(l, zero_crossings, marker="+")
ax.set_title("Number of zero crossing")
_ = ax.set_xlabel("$\lambda_l$")

We can also try to interpret what the eigen vectors are responsible for, by projecting it on the graph (similar to what we would do to analyse deep learning filters). In the figure below, it is clear that an eigen vector with higher eigen value leads to a higher frequency graph.
Some clear patterns can be distinguished, for example eigen vector #1 seems to be responsible for eastern sensors.
### Eigen vector plot and visualization
# {% raw %} /!\ This is specific for liquid to escape the braces
eig_to_plot = [1, 40, 120]
fig, ax = plt.subplots(nrows=2, ncols=len(eig_to_plot), figsize=(5*len(eig_to_plot), 10))
for ii, ii_eig in enumerate(eig_to_plot):
#eigen plots
img = ax[0, ii].plot(v[:, ii_eig])
ax[0, ii].set_title("$\lambda_{{{}}}={{{:.3f}}}$"
"".format(ii_eig, l[ii_eig]))
#eigen vectors on the graph
node_colors = np.array([val for val in v[:, ii_eig]])
img = nx.draw_networkx_nodes(nx_graph, pos,
node_color=node_colors,
cmap="jet", node_size=50, ax=ax[1, ii])
plt.colorbar(img, ax=ax[1, ii])
_ = ax[1, ii].set_title("$\mathbf{{v}}_{{{}}}$ on graph"
"".format(ii_eig))
#

2.4 Clustering¶
It is relatively easy to apply clustering, even with unlabelled data. What you want to do is perform a simple unsupervised clustering (like k-means) on the lowest eigen vectors. Why on the low frequencies? Because they carry the power of the signal, when the highest frequency carry the dynamic of the graph. Here we will try to use the first $5$ eigen vectors.
# kmean clustering
import sklearn
from sklearn.cluster import KMeans
sk_clustering = sklearn.cluster.KMeans(n_clusters=2, random_state=0).fit(v[:, :5])
This result in the clustering of some western sensors, interrestingly it does not cluster all the sensors on the same road, but just those who are on the same lane/direction. This is because of the constrain that we put on the graph, taking into acount correlation of the data!
### plotting
fig, ax = plt.subplots(figsize=(5, 5))
nx.draw_networkx_nodes(nx_graph, pos, nodelist=list(np.where(sk_clustering.labels_==0)[0]),
node_size=50, node_color='b', ax=ax)
nx.draw_networkx_nodes(nx_graph, pos, nodelist=list(np.where(sk_clustering.labels_==1)[0]),
node_size=50, node_color='r', node_shape="+", ax=ax)
_ = ax.set_title("Clustering the low frequency nodes")

2.5 Filtering¶
We saw in the mathematical background section that we can easily filter a signal in the spectral domain, let's implement this using eq \ref{eq:graphconv}.
# graph convolution
def graph_convolution(x, h, v):
'''Graph convolution of a filter with data
Parameters
----------
x : `np.array` [float], required
ND input signal in vertex domain [n_nodes x signal]
h : `np.array` [float], required
1D filter response in spectral domain
v : `np.array` [float]
2D eigen vector matrix from graph laplacian
Returns
-------
`np.array` [float] : the output signal in vertex domain
'''
# graph fourier transform input signal in spectral domain
x_g = v.T @ x
# convolution with filter, all in spectral domain
x_conv_h = h * x_g
# graph fourier inverse transform to get result back in vertex domain
out = v @ x_conv_h
return out
In classical signal processing, a filter can be easilly translated into the temporal domain. This is not possible in GSP (translate a filter into the graph domain), however it is possible to check its response in our system by convolving the filter with a dirac. Let's try to apply a heat filter on our graph and see its response in the vertex domain.
# heat filter
def heat_filter(x):
'''Heat filter response in spectral domain'''
out = np.exp(-10*x/np.max(x))
return (1/out[0])*out
### plot frequency response
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(l, heat_filter(l))
ax.set_xlabel("$\lambda_l$")
_ = ax.set_title("Heat filter frequency response")

Here is the result when applying the heat filter to $\delta_{0}$ (at the position of the node #400001 located at the interchange US 101/Miami 880).
# apply heat filter at the position of #400001
sensor_name = "400001"
_, sensor_idx = get_data_sensor(sensor_name=sensor_name, sensor_ids=sensor_ids)
dirac_from_sensor = np.zeros((num_nodes, 1))
dirac_from_sensor[sensor_idx] = 1
out = graph_convolution(x=dirac_from_sensor, h=heat_filter(l)[:, np.newaxis], v=v)
### plotting signal on graph domain
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 5))
node_colors = np.array([val for val in out.flatten()])
img = nx.draw_networkx_nodes(nx_graph, pos,
node_color=node_colors,
cmap="jet", node_size=50, ax=ax[0])
plt.colorbar(img, ax=ax[0])
_ = ax[0].set_title("$h \otimes \delta_0$")
ax[1].plot(out.flatten())
_ = ax[1].set_xlabel("node $i$")

This can help us interprate how the energy diffuse over the system, for this specific example it can be a tool for engineers to see where traffic congestion can happen. Good luck for the drivers in the center of bay area!
Applying this filter to the sensor measurements acts a (really) low pass filter, as you can see below.
# apply heat filter to all data
sensor_name = "400001"
_, sensor_idx = get_data_sensor(sensor_name=sensor_name, sensor_ids=sensor_ids)
out = graph_convolution(x=data, h=heat_filter(l)[:, np.newaxis], v=v)
### plot before and after filtering
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10,4))
ax[0].plot(data[sensor_idx, start:end_3])
ax[0].set_title("Sensor {} before filtering".format(sensor_name))
ax[0].set_ylim(10, 80)
ax[0].set_xlabel("Time")
ax[0].set_ylabel("Speed (mph)")
ax[1].plot(out[sensor_idx, start:end_3])
ax[1].set_title("Sensor {} after filtering".format(sensor_name))
_ = ax[1].set_ylim(10, 80)
plt.show()

Why is the resulting signal lower? I suppose this is because the offset component is partially canceled out after filtering (in our case the minimum frequency is not zero but $\lambda_0 = 0.048$).
Conclusion¶
This post guided you on how the graph signal processing theory was built, and how to apply it concretely. We saw a specific example using traffic data, and although we could go much further in the analysis, I hope it answered some of your questions
To go gurther¶
A first reference that helped me a lot for my understanding is the Stanford class CS224W: Machine Learning with Graphs. Also the Persagen Consulting web page which are specialized in molecular genetics, but still is a really good ressource.
The extension of GSP applied to deep learning is the hot topic of graph convolution networks (GCN). If you are curious about them definitively look at this wonderfull distill interactive post. Also, I was lucky to work with Dr Zhang specifically on applying GCNs to neuroimaging data (fMRI), check her work!
Finally, the set of tutorials from pygsp are also a great way to understand each component of GSP.
References ¶
1. Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781. (2013).
2. Nonato, L.G.: Graph Fourier Transform, (2017). https://doi.org/https://sites.icmc.usp.br/gnonato/gs/slide3.pdf.
3. Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907. (2016).
4. Hammond, D.K., Vandergheynst, P., Gribonval, R.: Wavelets on graphs via spectral graph theory. Applied and Computational Harmonic Analysis. 30, 129–150 (2011).
5. Li, Y., Yu, R., Shahabi, C., Liu, Y.: Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv preprint arXiv:1707.01926. (2017).
6. Leskovec, J., Faloutsos, C.: Sampling from large graphs. In: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 631–636 (2006).
7. Hagberg, A.A., Schult, D.A., Swart, P.J.: Exploring Network Structure, Dynamics, and Function using NetworkX. In: Varoquaux, G., Vaught, T., and Millman, J. (eds.) Proceedings of the 7th Python in Science Conference. pp. 11–15. , Pasadena, CA USA (2008).
8. Shuman, D.I., Narang, S.K., Frossard, P., Ortega, A., Vandergheynst, P.: The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE signal processing magazine. 30, 83–98 (2013).